Written by
hanhan
on
on
UNIX环境高级编程-读书进度记录
第1章 UNIX基础知识
- 结构:内核 -> 系统调用 -> shell + 公用函数库 -> 应用程序
- 登录,/etc/passwd文件中的内容, shell的多个实现版本,bash, dash, zsh…
- 绝对路径、相对路径
- 输入和输出 (第三章详细)
- 每运行一个新程序时,所有shell为其打开3个文件描述符:标准输入、标准输出、标准错误。若不特殊处理,都链接向终端。
- 不带缓冲的IO:open, read, wirte, lseek, close,read时自己指定BUFFERSIZE,不同BUFFERSIZE导致不同程序效率 (第三章详细说明)
- 标准IO:为不带缓冲的IO函数提供了一个带缓冲的接口。使用标准IO函数,无需担心如何选取最佳缓冲区(上述BUFFERSIZE)的大小。
- 程序和进程 (第十二章详细)
- 程序存储在磁盘上,内核使用exec函数(7个exec函数之一)将程序读入内存并执行
- getpid获取进程id
- 进程控制的主要函数:fork, exec(7种变体), waitpid
- fork 对父进程返回进程ID,对子进程返回0
- fork + exec == 某些操作系统所称的产生(spawn)一个新进程
- 进程 vs 线程
- 线程共享同一地址空间、文件描述符、栈、以及进程相关的其它属性
- 线程ID只在它所属的进程内起作用
- 进程模型&线程模型(第十二章详细说明)
- 出错处理
- UNIX系统执行出错时,通常返回负值
- 整形变量errno,在
中定义了所有常量 - strerror,将errno的值映射为出错消息的字符串,返回字符串指针
- perror,基于errno的值,在标准错误上产生一条出错消息
- 一般不直接使用strerror和perror,而是用附录B中的出错函数
-
中的出错可分为:致命 & 非致命 ,非致命可进行捕捉处理
- 用户标识
- 用户ID=0 为root用户(根用户/超级用户),口令文件 登录名到用户ID的映射。 getuid()
- 组ID,组名到组ID的映射,组文件/etc/group。 getgid()
- 用户ID和组ID用数值存储,是为:节省磁盘空间 + 检验权限时进行比较比字符串更快
- 附属组ID,一个用户可属于多至16个其它的组
- 信号 (第十章详细)
- 用于通知进程发生了某种情况
- 3种处理信号的方式:
- 忽略信号,不推荐
- 按系统默认方式处理
- 提供一函数,信号发生时调用该函数
- 终端键盘上有2中产生信号的方法:
- 中断键(ctrl + c)
- 退出键 (ctrl + \ )
- 调用kill函数也可产生信号
- 时间值
- UNIX系统使用过两种时间值:
- 日历时间,自1970.01.01 00:00:00 开始至今所累计的秒数值
- 进程时间/CPU时间,以时钟滴答计算
- 度量进程的执行时间,UNIX维护了三个进程时间值,获取方法:time命令
- 时钟时间,即墙上时钟时间
- 用户CPU时间,执行用户指令所用时间
- 系统CPU时间,进程执行内核程序所花时间。
- UNIX系统使用过两种时间值:
- 系统调用和库函数
- 系统调用:程序向内核请求服务的入口点
- UNIX所用技术是: 为每个系统调用在标准C库中设置一个同名函数,通过标准C调用序列来调用这些函数,然后函数调用相应的内核服务。
- 通用库函数,如printf
- 区别:
- 从用户角度看,其区别不重要
- (通用库函数中 使用/未使用 了系统函数,或者进行了封装)
@2017.12.30,用时2h
第2章 UNIX标准及实现
- UNIX标准化
- ISO C
- IEEE POSIX,可移植操作系统接口
- SUS,是POSIX的超及定义了一些附加接口
- FIPS
- UNIX系统实现
- SVR4
- BSD
- FreeBSD
- Linux
- Mac OS X
- Solaris
- 限制
- 编译时限制(如,短整型的最大值是什么),可在头文件中定义。
- 运行时限制(如,文件名有多少个字符),通过进程调用一个函数获得限制值。
- 与文件或目录无关的运行时限制(sysconf函数)
- 与文件或目录有关的运行时限制(pathconf函数,fpathconf函数)
- ISO C限制,所有编译时限制都在
头文件中 - POSIX限制
- XSI限制
- Sysconf, pathconf, fpathconf
第3章 文件I/O(不带缓冲的IO)
- 功能:打开文件,读文件,写文件;常用的5个函数:open, read, write, lseek, close
- 文件描述符
- 对内核,所有打开的文件通过
文件描述符引用。非负整数。 - 0:标准输入, 1:标准输出, 2:标准错误。 在POSIX.1标准中,0 1 2被替换成定义在
中的符号常量。 - 很多系统文件描述符的上限是63,早期是19(对单个进程而言)
- 对内核,所有打开的文件通过
- 函数open和openat
- 返回最小的最小的未用的文件描述符的值
- Openat比open多一个fd参数,是POSIX.1最新版本中新加的函数,目的在于:1.让线程使用相对路径名打开文件; 2.可以避免TOCTTOU错误
- TOCTTOU错误:安全漏洞,可颠覆文件系统权限
- 函数creat
- 创建一个文件,完全可用
open(path, O_WRONLY|O_CREAT|O_TRUNC, mode)代替
- 创建一个文件,完全可用
- 函数close
- 关闭一个打开文件,释放该进程加在该文件上的所有记录锁
- 当一个进程结束时,内核自动关闭它所有的打开文件
- 函数lseek
- 每个打开文件都有
当前文件偏移量,非负整数,表示从文件开始处计算的字节数 - 打开文件时,若不指定O_APPEND选项,偏移量被设为0
- lseek(fd, offset, whence)
- 不引起任何I/O操作,仅将文件偏移量记录在内核中
- 显式设置打开文件的偏移量,执行成功则返回新的偏移量
- 可用来判断所涉及的文件是否可以设置偏移量,若fd指向管道/FIFO/网络套接字,则返回-1
- 某些设备允许负的偏移量,所以 永远要用
== -1来判断是否能设置偏移量 - 文件偏移量可大于文件的当前长度,文件空洞,文件中的空洞不占用磁盘存储
- 每个打开文件都有
- 函数read
- 成功,则返回读到的字节数;出错,返回-1
ssize_t read(int fd, void *buf, size_t nbytes)- ssize_t,带符号整型
- size_t,不带符号整型
- void*,通用指针
- 函数write
- I/O的效率
- 测试所用的文件系统是linux ext4文件系统(磁盘块长度为4096字节),BUFFSIZE在4096字节及以后位置时,效率最高
- 文件系统,采用
预读技术,当检测到正顺序读取时,系统试图读入比应用所要求的更多数据。 - 测试时,每次都使用不同的文件副本,后一次运行不会在前一次运行的高速缓存中找到所需数据。
- 文件共享
- UNIX系统支持在不同进程间共享打开文件
- 内核使用3种数据结构表示打开文件,其关系可用下图精确描述。
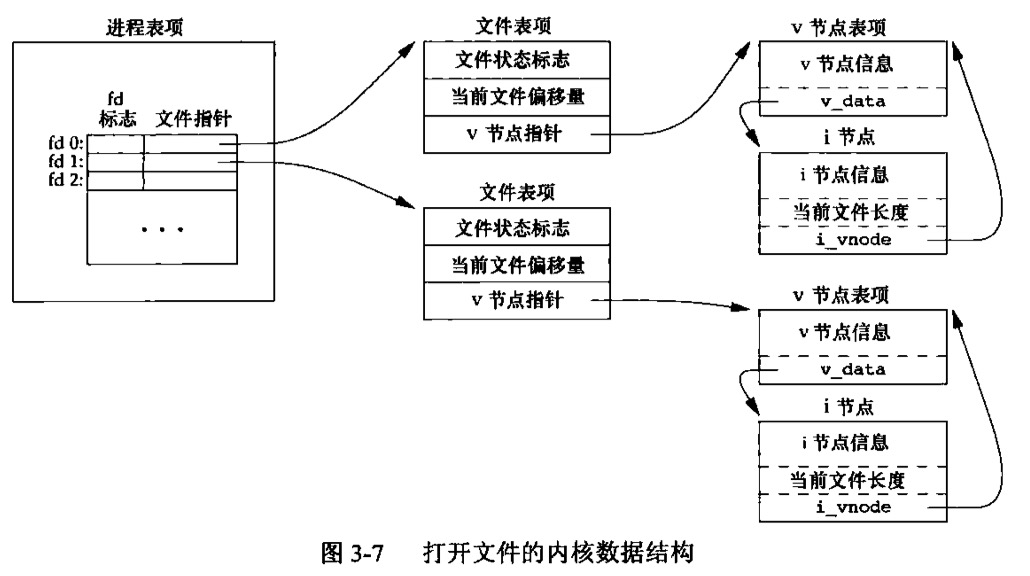
-
- 进程-进程表项。每个进程在进程表中有个记录项(PCB?),记录项包含一张打开文件描述符表,构成:fd标志+文件表项指针
-
- 内核-文件表项。内核为所有打开文件维持一张文件表,包含:
- 文件状态标志
- 当前文件偏移量
- 指向该文件v-node表项的指针
- 内核-文件表项。内核为所有打开文件维持一张文件表,包含:
-
- 文件-v-node表项。每个打开文件都有一个v-node结构,构成:文件类型+操作函数指针+i-node。打开文件时,从磁盘读入内存
- i-node包括:文件所有者、文件长度、指向磁盘位置的指针
- Linux没使用v-node,而是使用i-node结构 
- 文件-v-node表项。每个打开文件都有一个v-node结构,构成:文件类型+操作函数指针+i-node。打开文件时,从磁盘读入内存
-
- 一个文件被n个独立进程同时打开,就会有n个文件表项?
- 多个进程同时读取同一文件可正常工作
- 原子操作
- 早期UNIX系统不支持open的O_APPEND选项,通过 lseek到EOF + write完成append的功能。
- Lseek + write是两个操作,非原子,因此会有多进程同时操作时的冲突问题
- Open时设置O_APPEND标志,会原子操作,避免上述问题
- pread, pwrite 原子性操作
- pread,功能上相当于 lseek + read
- 区别在于:1. 原子性,不会产生中间状态 2.不更新当前文件偏移量
- 函数dup和dup2
- int dup(int fd)
- Int dup2(int fd, int fd2),相当于close(fd2) + fcntl(fd, F_DUPFD, fd2)
- 用于复制现有描述符,dup2中的fd2用于指定新描述符的值,若fd2已打开,则先将其关闭
- 函数sync, fsync, fdatasync
- 大多数磁盘I/O都通过缓冲区进行。
- 通常write只是将数据排入队列,实际的写磁盘操作在以后某时刻执行
- 延迟写(delay write):向文件写入数据时,内核先将数据复制到缓冲区中,再排入队列,晚些时候再写入内存。
- 为保证磁盘和缓冲区的内容一致性,UNIX系统提供sync, fsync, fdatasync函数
- sync(void), 将所有修改过的块缓冲区排入写队列,并返回。update这一系统守护进程会周期性地调用sync,以保证flush
- fsync(int fd), 只对指定的fd作用,且等待磁盘操作结束才返回
- 函数fcntl
- Int fcntl(int fd, int cmd, …)改变已打开文件的属性,有5种功能,通过指定cmd
- 复制已有fd
- 获取/设置fd标志
- 获取/设置文件状态标志
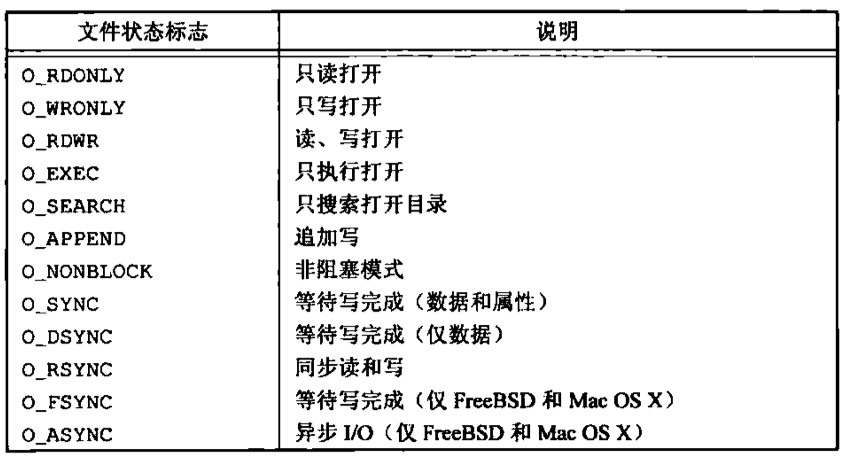
- 获取/设置异步I/O所有权
- 获取/设置记录锁
- 同步写 vs 延迟写
- 延迟写,先把数据排入到队列,等一定时间/一定量后一次性写入硬盘
- 同步写,同时写入到硬盘中
- Fd文件标志中的O_SYNC标志开启后,则使用同步写
- Int fcntl(int fd, int cmd, …)改变已打开文件的属性,有5种功能,通过指定cmd
- 函数ioctl
- 不能用本章上述其它函数表示的I/O操作都能用ioctl表示
- 终端I/O是使用ioctl最多的地方
因为read和write是**在内核执行**,所以称其为不带缓冲的I/O函数
@2018.01.05,用时大概3h
第4章 文件和目录
- 函数stat,fstat, fstatat, lstat
- 文件类型
- 普通文件(regular file)
- 目录文件(directory file)
- 块特殊文件(block special file),提供对设备带缓冲的访问
- 字符特殊文件,提供对设备不带缓冲的访问。系统中所有设备要么是字符特殊文件,要么是块特殊文件。
- FIFO,用于进程间通信的管道
- 套接字,进程间通信
- 符号链接(symbolic link),指向其它文件
第5章 标准I/O库
- 流和FILE对象
- 标准IO库的操作围绕流进行,用标准IO库打开/创建文件时,使一个流与文件关联
- ASCII字符集,一个字符对应一个字节
- 流的定向,决定读、写字符是单字节还是多字节(字节定向/宽定向)
- Fwide用于设置流的定向
- 标准输入、标准输出、标准错误
- 对一个进程预定义了以上3个流,可自动被进程使用
- 在头文件
中,通过stdin, stdout和stderr使用
- 缓冲
- 目的:尽可能减少read和write调用的次数(??减少IO操作次数吧,write只是排入到队列中?)read, write等文件IO为系统调用,最终为减少系统调用的次数。
- 标准IO库对每个I/O流自动进行缓冲管理
- 标准I/O提供三种类型的缓冲:
-
- 全缓冲。在填满标准IO缓冲区后才进行实际IO操作。malloc获得需使用的缓冲区。flush是标准IO缓冲区的写操作,将缓冲区中的内容(可能是部分填满)写到磁盘上。
-
- 行缓冲。在输入和输出中遇到换行符时,标准IO库执行IO操作。
- 注意,当缓冲区填满时,即使没遇到换行符,也要进行IO操作
- 行缓冲。在输入和输出中遇到换行符时,标准IO库执行IO操作。
-
- 不带缓冲。标准IO库不对字符进行缓冲存储
-
- 标准错误流stderr不带缓冲,以便错误能尽快显示
- 若是指向终端设备的流,则是行缓冲;否则是全缓冲。
- Setbuf 打开/关闭缓冲机制,setvbuf 设置缓冲类型
- 一般而言,应由系统选择缓冲区的长度,并自动分配缓冲区
- Fflush(File *fp),强制冲洗一个流,使所有未写数据都被传送至内核
- 打开流
- fopen, 打开路径名指定的文件
- freopen,在一个指定的流上打开一个指定的文件。一般用于将一个文件打开为一个预定义的流
- Fdopen,取一个已有的fd,并使一个标准IO流与此fd关联
- UNIX内核不区分
文本文件和二进制文件,但在上述函数中指定type中的字符b,可以让标准IO系统进行区分。 - 若多个进程用标准IO的追加写方式打开一个文件(O_APPEND标志),那文件数据还是正确且安全的。(追加写是原子操作)
- 若流引用系统终端设备,则默认流是行缓冲的;否则,默认都是全缓冲的
- Fclose关闭一个打开的流,关闭之前,先冲洗,缓冲区中的任何输入数据都被丢弃(??为何是丢弃,而非进行一次IO写?)
- 当一个进程正常终止,所有未带写缓冲数据的标准IO流都被冲洗,所有打开的标准IO流都被关闭
- 读和写流
- 三种类型的非格式化IO:
-
- 每次一个字符的IO, getc, fgetc, getchar, putc, fputc, putchar
-
- 每次一行的IO, fgets fputs
-
- 直接IO,常用于从二进制文件中读写一个结构
-
- 在大多数实现中,每个流在FILE对象中维护了:出错标志 + 文件结束标志
- Ungetc可以将从流中读取的字符再压送回流,读出顺序与押送回顺序相反(队列?)。只是压送到缓冲区中,并没写到底层文件/设备中。
- char *gets(char *buf);
- char *fgets(char *restrict buf, int n, FILE *restrict fp);
- gets从标准输入读,fgets从指定流中读。两个函数都得指定缓冲区地址。会一直读到下一个换行符为止,读入字符被送入缓冲区,若缓冲区长度不够,则只返回一个不完整的行。
- Gets不推荐使用,因为无法指定缓冲区长度(默认长度多少?),缓冲区溢出漏洞。所以永远使用fgets而非gets
- fputs将一个以null字节终止的字符串写到指定的流,尾端的终止符null不写出。通常在null字节前是一个换行符,但并不要求总是如此。
- Puts将一个以null字节终止的字符串写到标准输出,null不写出,随后再写一个换行符到标准输出。 Puts没有安全隐患,但还是推荐使用fputs自己控制最后一个换行符的输出。
- 三种类型的非格式化IO:
- 标准IO的效率
- exit函数会冲洗任何未写的数据,然后关闭所打开的流(详细在8.5节)
- 标准IO库与直接调用read write函数相比并不慢很多(用户CPU时间是read的10倍)。对于大多数复杂的应用程序,最主要的用户CPU时间是由应用本身的各种处理消耗的,而不是由标准IO例程消耗的。(??用户CPU时间消耗)
- 二进制IO
- fread, fwrite
- 读/写二进制数组
- 读/写一个结构
- 使用二进制IO的问题是,只能用于读在同一系统上已写的数据
- fread, fwrite
- 定位流
- 格式化IO
- 5个printf函数
- printf, 将格式化数据写入到标准输出
- fprintf,写到指定的流
- dprintf,写到指定fd
- sprintf,写入数组buf。这里当写入长度大于数组长度时会有缓冲区溢出。
- snprintf,解决上面的缓冲区溢出问题,当大于数组长度时会被丢弃
- 具体格式化的标志、参数等等,不展开了。
- 实现细节
- 每个标准IO流都有一个与其关联的fd,对一个流调用fileno以获得其fd
- int fileno(FILE *fp)
- 内存流
- 标准IO的替代软件
- 标准IO效率不高,当使用fgets和fputs时,通常需要复制两次数据:1. 内核和标准IO缓冲区间(调用read write时) 2. 在标准IO缓冲区和用户程序的行缓冲区之间。(???)
第6章 系统数据文件和信息
- 口令文件 /etc/passwd,组文件 /etc/group
- 口令文件是ASCII文件
- 用户名:加密口令:数值用户ID:数值组ID:注释:初始工作目录:初始shell
- 为阻止一用户登录系统,可使用/dev/null,可将登录shell设为/bin/false
- 使用nobody用户名的目的,任何人都可登录系统,但其用户ID(65534)和组ID(65534)不提供任何特权,只能访问人人皆可读写的文件。
- 阴影口令文件 /etc/shadow
- 附属组,一个用户可以同时属于多个组。
- uname函数返回与主机和操作系统有关的信息
@2018.01.10 用时大概3小时
第7章 进程环境
⁃ main函数 ⁃ 在内核执行C程序时,在调用main前先调用一个特殊的启动例程,可执行程序文件将此启动例程指定为程序的起始地址 ⁃ 进程终止 ⁃ 8种终止方式,其中5种为正常终止 ⁃ 1. 从main返回 ⁃ 2. 调用exit ⁃ 3. 调用_exit或_Exit ⁃ 4. 最后一个线程从其启动例程返回 ⁃ 5. 从最后一个线程调用pthread_exit ⁃ 6. [异常]调用abort ⁃ 7. [异常]接到一个信号 ⁃ 8. [异常]最后一个线程对取消请求做出相应 ⁃ exit函数相对于_exit和_Exit的区别是,exit会做些标准IO库的关闭清理工作:对所有打开的流调用fclose,会调用在atexit()注册的函数 - 从程序设计角度看,main的返回类型应是带符号整型
- atexit函数,把一些函数注册为退出函数(程序退出时的回调函数);终止处理程序,每登记一次,就会被调用一次。
- C程序的存储空间布局
- 高地址->低地址:命令行参数和环境变量, 栈, 堆,未初始化的数据,初始化的数据,正文。
- 初始化的数据和正文会被存在磁盘程序文件中(不是内存?),未初始化数据段的内容不会存放在磁盘中(理解:只记录数据位置和大小,因为未初始化,所以没有必要存储)
- 共享库函数的副本, 被以动态链接的方式调用
- 存储空间的分配
- malloc,分配指定字节数的存储区,未初始化
- calloc,每一bit都初始化为0
- realloc,增加/减少以前分配区的长度
- 分配例程通常用sbrk系统调用实现,可扩充或缩小进程的堆。但大多数malloc和free的实现都不减小内核的存储空间,释放后的空间可供再分配,但将他们保持在malloc池中而不返回给内核
- C中的goto语句只能在同一函数内跳转。
- setjmp 和 longjmp提供了跨栈帧的跳转,适用于深层嵌套函数调用中的异常处理
- getrlimit, setrlimit,获取/设置资源限制。
@2018.01.12,用时1.5h
第8章 进程控制
- 进程标识
- 进程ID可复用。大多数UNIX系统实现
延迟复用算法,赋予新建进程的ID不同于最近终止使用进程所使用的ID,为了防止新进程被误认为是使用同一ID的某个已终止的进程。 - ID=0,swapper进程,系统进程,是内核的一部分,不执行磁盘上的任何程序。
- ID=1,init进程,用户进程,但以超级用户特权运行,在自举过程结束时由内核调用,启动一个UNIX系统,读取与系统有关的初始化文件,绝不会终止。
- 进程ID可复用。大多数UNIX系统实现
- 函数fork
- pid_t fork(void); 创建新进程,调用一次,返回两次,子进程返回0,父进程返回子进程ID。
- 父进程返回子进程ID:因为不存在一个可以返回一个进程所有子进程的函数。
- 子进程返回0:getppid可以获得其父进程的ID,且ID=0被swapper进程占用,不会冲突,所以可用来标志
- 子进程和父进程继续执行fork调用后的命令(所以执行至少两次),而具体的执行次序是取决于内核的调度算法
- 子进程和父进程不共享存储空间:数据空间、堆栈,而是以副本形式存在。只共享正文段。
写时复制,因为fork之后经常跟着exec,所以很多实现并不执行一个父进程的数据段和堆栈的完全副本,而是有一块共享区域,内核设置其访问权限为制度,若父进程或子进程试图修改此共享区域,则内核为修改区域的那块内存(通常是一页)制作一个副本。(我的理解是不用完全复制,效率更高)strlenvssizeof- strlen 进行一次函数调用,长度不包含终止null字节
- sizeof 在编译时计算长度(编译时已知,故不需要函数调用),包含终止null字节
- 重温:标准输出是行缓冲,输出到文件设备是全缓冲。
- fork时,父进程的文件描述符被复制到子进程中,且共享同一个文件偏移量。所以需要控制父子进程间的同步。以下两种比较常见:
-
- 父进程等待子进程完成(追加写到子进程的偏移量之后)
-
- 父进程和子进程各自执行不同的程序段,父子进程关闭自己不需使用的fd,取消共享。此方法是网络服务进程常用的。
-
- 除了fd,父进程的以下属性也由子进程继承:实际用户ID、实际组ID、…,资源限制,环境,当前工作目录,根目录….
- fork失败的两个原因:
-
- 系统中已有进程数太多
-
- 该实际用户ID的进程总数超过了熊限制。 由
CHILD_MAX限制
- 该实际用户ID的进程总数超过了熊限制。 由
-
- 某些操作系统将 fork + exec 封装成 spawn
- 函数vfork
vforkvsforkfork,子进程有父进程的完整副本,调度顺序不一定vfork,子进程与父进程共享数据段,子进程先于父进程运行,直到子进程调用exec或exit,父进程才运行(这里如果子进程依赖于父进程的条件,可能产生死锁) 子进程在父进程的地址空间中运行
- 函数exit
- 正常终止
- main函数内调用return,等同于exit
- 调用exit。调用在atexit注册的终止处理程序、关闭标准IO流
- 调用_exit或_Exit。不冲洗标准IO流
- 进程的最后一个线程在其启动例程中执行return语句
- 进程的最后一个线程调用pthread_exit函数
- 异常终止
- 调用abort。产生SIGABRT信号,这是下一种终止情况的特例
- 当进程接收到某些信号时。
- 最后一个线程对取消请求做出响应。
- 进程终止后,都会执行内核中的同一段代码,关闭所有打开的fd,释放它所使用的存储器。
- 终止进程需要知道其父进程是如何终止的
- 正常终止,是退出状态
- 异常终止,是终止状态
- 终止进程的父进程能用
wait和waitpid取得终止状态。 - 子进程将终止状态返回给父进程
- 孤儿进程:父进程先于子进程终止。孤儿进程的父进程都变为init进程。
- 在一个进程终止时,内核逐个检查所有活动进程,若是正要终止进程的子进程,则将其父进程ID设为1
- 内核为每个终止子进程保留了一些信息:进程ID+进程终止状态+进程使用的CPU时间总量,终止进程的父进程调用
wait和waitpid可获得 - 僵尸进程:子进程已终止,但父进程还没调用wait waitpid让内核释放子进程信息。(10.7中介绍如何避免产生僵尸进程)
- init的子进程永远不会是僵尸进程,因为合理编写了
- 正常终止
- 函数wait和waitpid
- 当一个进程正常/异常终止时,内核向其父进程发送SIGCHLD信号
- 父进程可忽略信号,也可以执行回调函数
- 调用wait/waitpid时:
- 若子进程都在运行,则阻塞
- 若某个子进程已终止,则立即返回终止状态
- 若没子进程,则出错返回
- 收到SIGCHLD信号调用时,调用wait会立即返回;若随机调用wait,则会阻塞
waitvswaitpid- pid_t wait(int *statloc);
- pid_t watipid(pid_t pid, int *statloc, int options)
- waitpid支持非阻塞返回(对于子进程都在运行的情况)
- waitpid可以等待特定线程
- waitpid包含了wait的所有功能
- 只要有一个子进程终止,
wait就返回。在早起UNIX实现中,为了等待特定进程,wait需要把返回的pid与期望pid比较,若不是期望的,则先保存,继续调用wait waitpid中的pid可以指定所期望等待的进程
- 函数waitid, 类似于
waitpid,但更灵活 - 函数wait3和wait4, 允许内核返回由终止进程及其所有子进程使用的资源概况:用户CPU时间总量,系统CPU时间总量,缺页次数,接收到信号的次数
- 竞争条件
- 共享资源 + 最后结果取决于进程运行顺序
- 父进程等待子进程终止:wait/waitpid
- 子进程等待父进程终止
- 轮询,判断getppid()是否为1;浪费CPU
- 信号。
- 函数exec
- 调用exec时,会执行
正文段、数据段、堆、栈的替换 - exec系列有7个函数,其中只有execve是系统调用
- 调用exec时,会执行
- 在设计应用时,使用
最小特权模型 - 解释器文件:文本文件,起始行指定解释器
- 函数system,执行一个命令字符串
- 进程会计
- 每当进程结束时,内核就会写一个会计记录:CPU总时间,用户ID,组ID,启动时间
- 无法获取永不终止的进程的会计记录,如内核守护进程
- 用户标识,实际用户ID,有效用户ID,组ID
- 进程调度
- 特权进程可以
提高调度权限 - 非特权进程只能调整nice值(0是最高),nice值越小,优先级越高
- nice值的改变会影响该进程对CPU的占用率
- 特权进程可以
@2018.01.16,用时3h