on
读书笔记-Kafka权威指南
一二章部分内容
producer发送流程:
- producer发送message到broker。
- Broker commit到本地存储。确认模式取决于request.required.acks=0/1/all参数设置。
- 等broker确认后,producer继续发下一条。
硬件选择:
- 硬盘吞吐量,最直接影响producer clients的性能。大多数producer clients都至少等待一个broker的确认,所以磁盘写速度越高意味消息发送吞吐率越高。
- 硬盘容量,可以存足够时间的messages。
- 内存,consumer一般从partition末端读取,[它不会跟生产者产生消息的时间差距很大,在此情况下,消息一般都是直接缓存在page cache,消费者直接从page cache读取]。page cache(页缓存)需要使用内存,kafka broker上最好不要部署其它应用,主要是为了避免共享page cache。
- 网络,kafka会占用很大的网络带宽,多consumer时,考虑kafka在传输和读取上的压力。
- CPU,相对于磁盘、内存而言不是很重要。producer产生的消息会被压缩存储,这部分需要用到CPU能力。 综上,kafka broker部署的机器需要是:大内存、SSD/HDD多路径或HDD磁盘阵列。
Kafka clusters:一般是指多个broker,主要为了分担负载。 Replication:指partition的replication,主要为了数据的容灾。
集群大小的选择:
- 需要多少磁盘容量。若需要保留10TB数据,单个broker可以保留2TB,则显然至少需要5个broker。
- 需要什么程度的集群处理能力,主要是考虑吞吐率。
第三章 Kafka Producers
第三方客户端:kafka第三方提供了C++、Python、Go等多种语言实现的客户端,实现了二进制线协议。虽然Kafka是用Java实现的,但通过这些第三方客户端可以在多种语言里享用Kafka。
生产者的多种不同需求:能否忍受消息丢失?能否忍受消息重复?是否有严格的latency要求?即常见的At most once, At least once, Exactly once 三种需求。
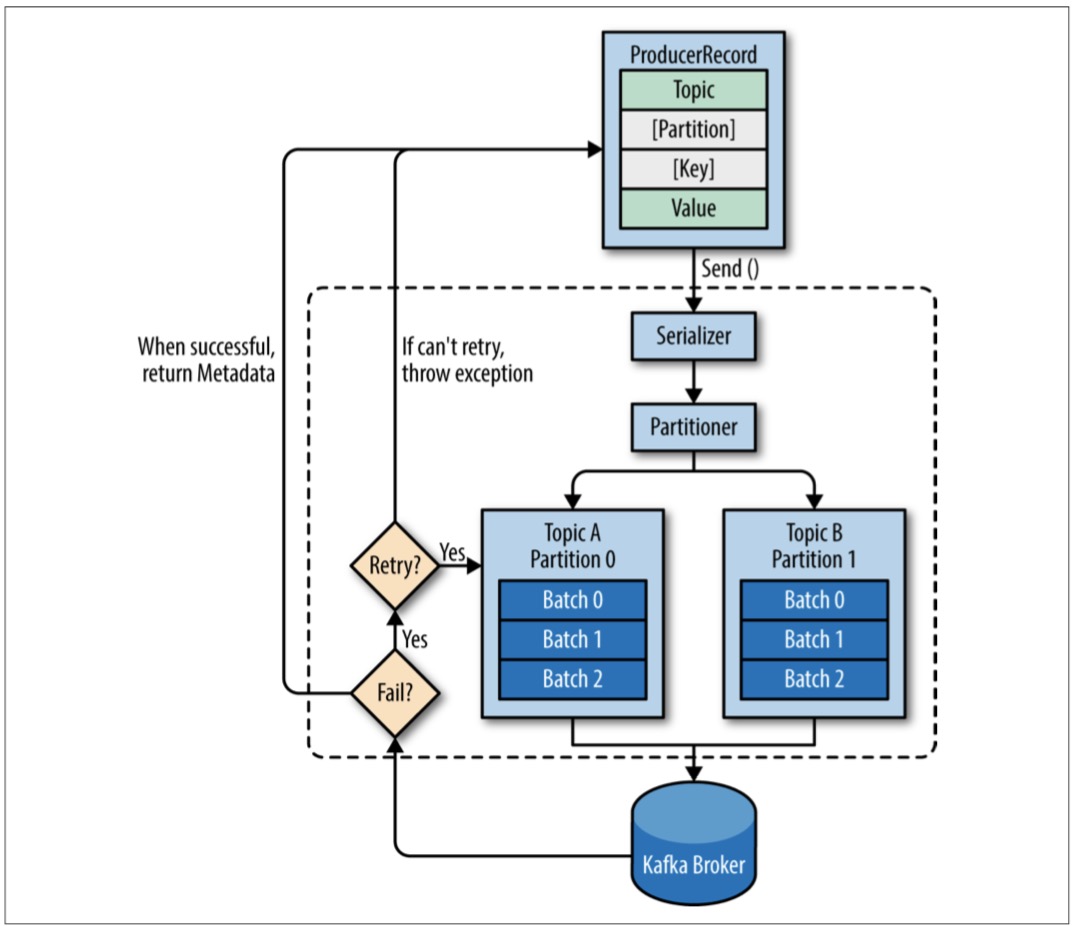
发送步骤:
- 创建ProducerRecord,指定topic。key/partition可选。
- 序列化,key and value对象 → ByteArrays,以便在网络中进行传输。
- 数据被发送到partitioner。如果在创建ProducerRecord时指定了partition,partitioner不做事情;否则会选择一个partition。这时producer确定了topic+partition。
- 一个单独的线程负责将topic+partition中的记录以batch方式发送给kafka broker。(猜测,在发送给broker前是放内存的)
- Kafka broker收到消息后回ack。如果消息成功写入,返回RecordMeatadata对象,包括topic、partition、记录在partition中的偏移;如果消息写入失败,返回error。
- 当producer收到ack时,会发下一条;当收到error时,根据配置决定是否重试、重试次数,若失败则返回error。
创建kafka producer的三个强制属性:
- bootstrap.servers,以host:port的列表形式指定kafka cluster地址。
- key.serializer,用于序列化的类。java对象 → 字节数组(byte arrays)。
- value.serializer,跟key.serializer差不多。
3种消息发送模式:
- 发送后就不管。由于kafka的高可用,这种模式下,大多数消息都会成功到达,但的确会丢失消息。
- 同步发送。会阻塞。send()方法返回一个Future对象,我们使用get()方法在future上等待来看send()是否调用成功。
- 异步发送。send()方法调用时带一个callback,当从kafka broker收到response时callback会被触发。
3种消息发送模式的写法:
- producer.send(record)。“发送后就不管”的发送模式。
- 调用send()方法时,消息被放在buffer中,然后由上述的一个单独线程发送。
- 序列化是调用send()方法时执行的操作,而不是构建ProducerRecord时执行的。所以在调用send()方法时,可能出现的异常有:SerializationException,BufferExhaustedException/TimeoutException (buffer满时),InterruptedException(负责发送的线程被中断)。
- producer.send(record).get()。同步发送模式的写法。会阻塞直到Future Obj有了返回结果。
- producer.send(record, new ProducerCallback())。异步发送模式的写法,不会阻塞,且能拿到发送结果。ProducerCallback类需要实现CallBack接口。
一系列producer配置参数中,除acks还有比较重要的是max.in.flights.requests.per.session=1,这可以保证重试时数据的顺序还是和发送顺序一致的。避免 batch1(失败)- batch2(成功)- 1(重试,成功)这种情况导致顺序错乱。
序列化一般使用StringSerializer和现成的Serializer,实在有必要再自己构建。
Parition的策略也可以自己定制。
第四章 Kafka consumers
Rebalance,重新调整的是一个consumer group中的哪些consumer消费哪些partition。
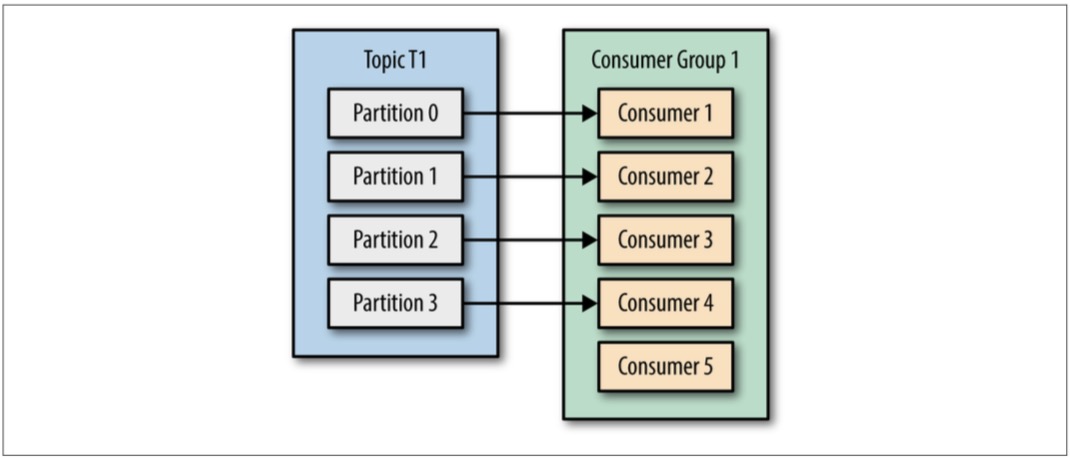
- 对于一个topic,其里面有N个partition,当consumer group中consumer的数量>N时,会有consumer处于空闲状态,得不到数据。所以当producer速率>consumer时,增加consumer数量是好办法,但是consumer数量上限不要超过partition分区数量,不然纯属浪费。意味着,一个partition不会被一个consumer group中的多个consumers同时消费。
- 划分consumer group的概念是为了将应用程序-consumer group对应起来,让每个应用程序可以获取topic中的所有信息,即从所有partition而非一个子集中获取信息。
- 分区的rebalance:partition随着consumer group中consumer的加入/离开而发生被消费变化:当一个consumer新加入时,会消费之前由其它consumer消费的partition;当一个consumer离开时,会把曾消费的partition给其它consumer消费。在rebalance期间,consumer不能消费。(应该是抛error)
- Consumer通过给kafka broker发心跳来看是加入/离开的。这个收心跳的broker称为group coordinator。
创建kafka consumer的三个强制属性:
- bootstrap.servers
- key.deserializer
- value.deserializer。这三个跟producer很相似,除了做serialize/deserialize的相反功能。
非强制但重要属性:
- group.id,所属的consumer group。会频繁用到。
commit an offset
- 目的:更新parition中位置。
- kafka中有个特殊的主题:
__consumer_offsets,记录了每个partition的committed offset。当consumer 崩溃/退出/新加入时,触发rebalance过程,每个consumer可能被分配到一个新的partition,为了让consumer知道从哪开始继续消费,需要读取每个partition的最新committed offset,并从这个offset继续。 - 在rebalance后,因为patiton-consumer的重新分配,可能导致“重复消费”/“消息丢失”的情况?❓重复消费可理解,为何会丢失,不是至少有consumer消费到了才会提交commit吗。
commit offset的几种方式:
- 自动commit。配置enable.auto.commit=true,每固定时间(默认5s) consumer会提交从poll()方法中返回的最大offset。后果:某些窗口内的事件会被消费2次,通过缩小commit间隔可以减少重复消费事件的窗口大小。越小间隔,越小数量的重复消费。但越小间隔意味着性能开销越大,需要有trade-off。
- 手动显式commit。设置auto.commit.offset=false,然后程序中调用consumer.commitSync()显式提交。commitSync()会提交poll()返回的最新offset,失败会重试。后果:重复消费。
- 异步commit。调用方法:consumer.commitAsync()或 consumer.commitAsync(callback)。commitAsync()没有失败重试,是因为由于异步会立即返回,后续可能有成功的commitAsync,再重试成功的话会写回旧值。一个简单可行的异步重试机制是使用递增ID,commit时比较callback返回的ID与当前ID。
- 使用同步+异步commit。日常使用consumer.commitAsync(),但在finally中进行consumer.close()之前,执行一次consumer.commitSync()。
- Commit特定偏移量。上述的commit只能提交最后返回的偏移量。
Rebalance listeners: 目的:在partition rebalance之前做一些offset commit或清理工作。譬如在失去对这个partition的ownership前进行offset提交和文件handler关闭等。
指定消费的offset:可以从头(seekToBeginning)、从尾(seekToEnd)或中间一个特定的地方开始。
consumer.poll()放在一个无限循环中,会不断消费。关于如何退出:在另一个线程中调用consumer.wakeup().
第五章 Kafka Internals
kafka使用zookeeper做集群管理。每个broker有个唯一的ID。ZK中:/brokers/ids
The Controller:是一个特殊的kafka broker,额外负责选举partition leader。会在ZK中创建/controller临时节点。broker在控制节点中创建zookeeper watch以便收到此节点变更的通知。当controller停止/失去与ZK的连接时,/controller节点会消失,其它brokers通过zookeeper watch捕捉到此信息然后都尝试建立/controller节点,第一个创建成功的会变成新的controller。
利用ZK临时节点的特性选举controller,controller负责选举partition leaders。
Replication
- 对partition而言,有leader & followers。follower的作用只是与leader保持同步做backup,而不会接受客户端请求。
- followers给leader发Fetch请求,以拿到offset。
- Leader会有某种策略判断follower是不是还在in-sync,通常是看某follower在10s内是否有请求,或10s内是否跟上了最近的请求。如果判断某follower没有保持同步,那这个follower失去了在下次发生灾难时成为leader的资格。
Request Processing
- Kafka使用基于TCP的二进制协议,指定了请求格式和brokers的响应格式。
- 在请求头部中包括:
- 请求类型(也叫API key)
- 请求版本
- correlation ID
- Client ID
- 对broker监听的每个端口,broker运行一个acceptor线程。acceptor线程会创建连接并将转给processor线程处理,processor线程可以配置多个。
- 请求类型(请求由broker接收):
- Produce requests。由producer发送的。
- Fetch requests。由consumer和follower partitions发送的
- Metadata requests。
- Other requests。
- Produce requests和fetch requests必须发到leader partition中。如果一个broker收到请求,但leader在另一个broker中,会返回给client“Not a Leader for Partition”的错误。Kafaka客户端会负责把produce和fetch请求发到包含leader partition的broker中。
- Kafka客户端通过metadata请求明确发给哪个broker。metadata响应中包含了partition分布信息,Leader partition信息等,并且所有的broker都有 metadata cache存储这个信息。client可以发给每个broker,获取一个全局信息缓存下来+定期/不定期刷新,然后决定发到哪个broker中。
- produce requests,broker可设置ack=0/1/all。0:只要消息发出去了,就认为被写入成功;1:只要leader ack,就认为写入成功;2:全部partition都要ack,才认为写入成功。broker收到produce request后,将消息写入文件系统buffer,就ack,buffer会不定期被flush到磁盘中。
- Fetch requests,consumer指定topic, offset, 返回数据的上限Limit和下限limit(上限limit是防止broker返回的数据太大以至consumer内存不够存;下限limit是为了减轻CPU和网络开销)。kafka使用零拷贝将信息发送到客户端。零拷贝的意思是:将 文件/linux文件系统缓存 中的消息直接发送到网络通道,而无需任何中间缓冲区(一般只本地缓存)。零拷贝性能提升很多。大多数时候consumer只能消费被所有in-sync replias都复制过的数据,而不是leader partition上的所有数据,否则会导致unsafe,这就是所谓的HW(高水位)。
- Other requests,brokers之间发送用的,很多种。
物理存储 存储的基本单位是partition,partition不可再分割。
- 分区分配。基本就是考虑在Host上分布的均衡,以及考虑机架的影响,如果有多机架的话,不要全放一个机架上。
- 文件管理。kafka不会永久地保存数据,或等待所有消费者消费后才删除。可配置最大保留时间和最大数据保留量。由于从一个大文件中删除一部分是费时且易出错的,所以把每个partition分成一系列segments。每个partition中的每个segment都会有一个open file handle,因此open file handles数量会非常高,OS必须做相应调整。
- 文件格式。每个segment被存在单独的文件中,里面存储了kafka消息和偏移量。文件格式与producer->broker和broker->consumer文件格式相同,主要是为了零拷贝优化。
- 索引。kafka允许从特定offset进行消费,意味着必须快速定位到此offset并读取。为此,kafka为每个partition构建索引。segment也有索引,以便删除用。
- 压缩。可设置保留策略为delete/compact。delete就是日常策略,会删除比retention time更老的事件;compact策略中,对topic中某特定的key,只会保留最新值。如果topic不包含key,那么compact策略会失效。
第六章 Reliable Data Delivery
kafka提供的保证:
- 顺序保证。同一partition中先被写入的先被消费。
- 当生成的消息在所有同步副本中被写入分区后,就被视为“已提交”。
- 只有至少有一个同步副本存活,被提交的消息就不会丢失。
- 消费者只能消费 已提交的消息。
in-sync和out-of-sync。注:如果看到一个或多个副本频繁的在in-sync和out-of-sync状态间切换,那么这基本可以说明集群配置有问题。其中常见的问题之一是java GC的错误配置。错误的配置可能导致GC期间broker停顿几秒,然后就变成out-of-sync。
broker reliable broker配置的三个参数:
- 复制因子。replication.factor,推荐replication.factor=3。以及建议通过broker.rack给每个broker配置机架名,以保证partition的副本可以跨机架分布。
- 不洁leader选举(是否允许out-of-sync中的副本成为Leader)。unclean.leader.election.enable,默认为true。场景是,当in-sync副本中只有leader且leader挂了时,要在”不选新Leader,partition则会一直为离线状态(可用性)” 和 “从out-of-sync副本中选新leader,则下游可能各种不一致数据(一致性)” 中作出艰难选择。 如果对数据一致性有非常高要求,这个参数就应该设为false。
- 最小in-sync副本数。min.insync.replicas=N,当消息被至少N个in-sync副本写入后,才被认为已提交。也就是说,如果in-sync中副本数小于N,消息肯定无法被接收。(这个参数的配置主要是为了防止在不洁leader选举中做出艰难选择)
producer reliable
- 发送ack。ack=0/1/all。0:只要发出就OK;1:leader收到就OK;all:所有in-sync副本都收到。
- 配置重试次数。可以配置为无限尝试,例如kafka mirrormaker工具。
- 额外的错误处理。producer自己会有错误处理,除此之外,开发者要关注程序中的错误处理。如:不可重试的broker错误、在消息发送给broker前的错误、重试次数或内存耗尽时的错误。
consumer reliable consumer几个重要的参数配置:
- group.id,标识consumer group。
- auto.offset.reset=earliest/latest,此参数控制消费者未提交offset或要求broker中不存在的offset时将执行的操作。
- enable.auto.commit,自己手动提交还是自动提交。设为true的主要好处是实现消费者时无需担心提交这件事。
- auto.commit.interval.ms,和第3个参数绑定,默认是5s。
第七章 构建数据管道
跳过。
第八章 跨集群数据镜像
kafka内置的跨集群复制工具:MirrorMaker。
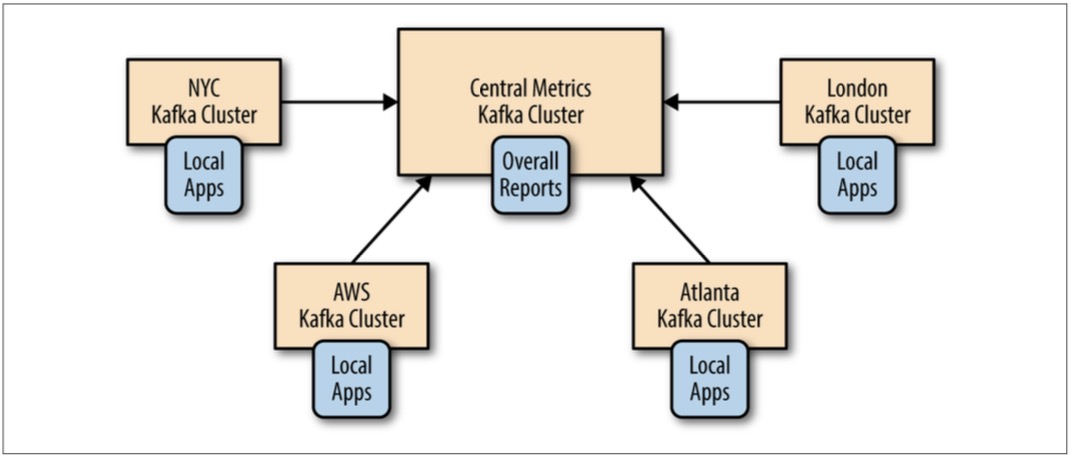
- hub-and-spokes架构。适用场景:一个中心kafka集群对应多个本地kafka集群。不足:一个DC的程序无法访问另一个DC的数据;本地DC的程序无法访问到全局数据。
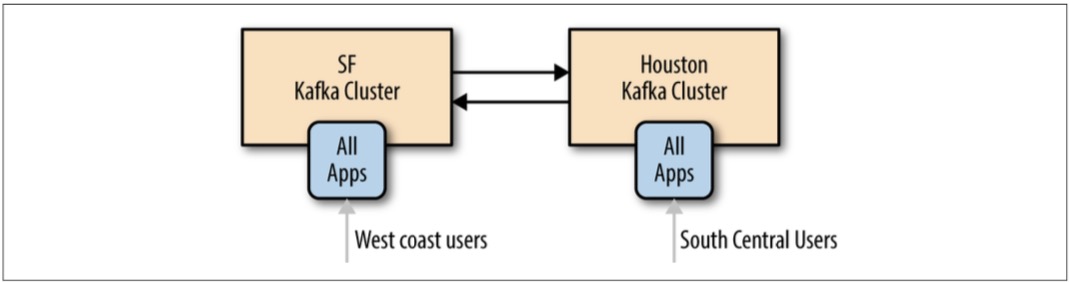
- 双活架构。适用场景:两个+的DC需要共享数据。优势:为就近用户提供服务,性能优势;冗余和弹性。不足:异步读取和异步更新时的冲突问题需要开发人员考虑周全;循环镜像问题。
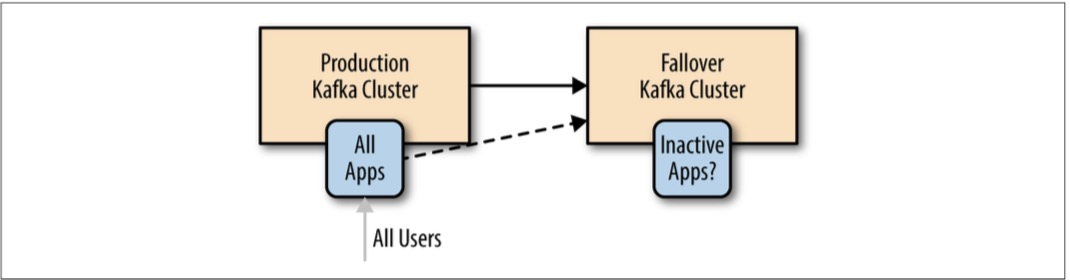
- 主备架构。适用场景:对kafka集群的失效备援。不足:只是为了灾备,是对集群的浪费。
- 延展集群。适用场景:当整个DC(而非kafka集群)发生故障时,避免kafka集群失效。
kafka的MirrorMaker
本质上是由一个生产者线程和多个消费者线程组成的进程。MirrorMaker是高度可配置的。
其它跨集群镜像方案 ⁃ uber的uReplicator ⁃ confluent的Replicator